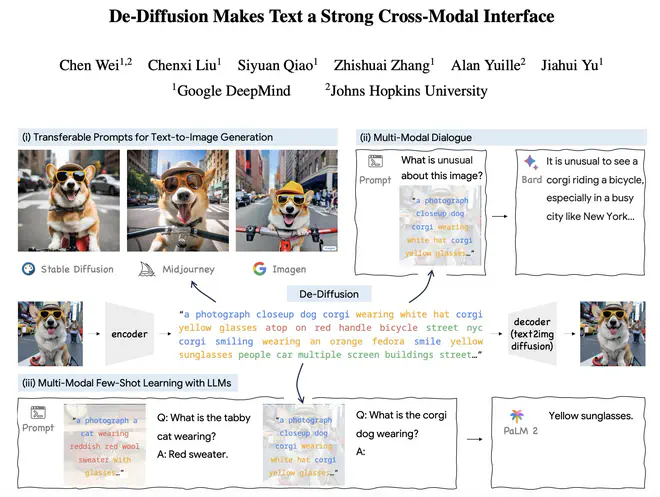
De-Diffusion 的算法思路非常简单粗暴:
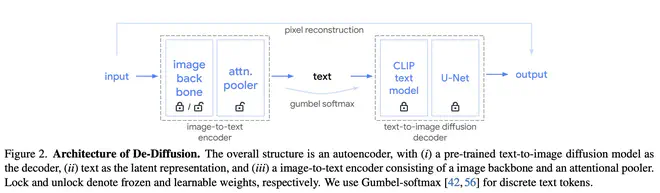
- 图片经由预训练(或从头训练)的 Encoder 编码得到 embeddings,然后这些 embeddings 作为 AttentionPooler 中 cross-attention 层的输入,与 AttentionPooler 自带的 Learned Queries 互相 attention,得到固定长度的 token 序列,送入一个 linear 层变成 CLIP Text Encoder 的离散词表中对应的 embedding。
- 整个优化过程只用到了 Diffusion Loss,梯度经过 U-Net,CLIP Text Encoder 传给 AttentionPooler (或者可能的 Visual Encoder)。
- 从 AttentionPooler 的输出到 CLIP Text Encoder 输入这一过程涉及到连续变量离散化的问题,作者选用了 Gumbel Softmax 保证梯度能被回传。
De-Diffusion 的训练方案与最近的 DreamLLM、Kosmos-G 等几篇文章有共同的地方,都是直接用 Diffusion Loss 经由 fixed U-Net 传递梯度优化 conditioner。De-Diffusion 的训练过程不需要 caption 数据,只需要图片。
具体实现上:
- 为了增加网络输出 text 的信息密度,De-Diffusion 剔除了 CLIP Text Encoder 词表中的标点符号。相当于删除了词表中 6%的内容。
- Diffusion 模块使用 Imagen U-Net(生成 64 图片的那个),Text Encoder 是 OpenCLIP ViT-H/14,AttentionPooler 有 75 个 Learned Queries,包含 5 层 Transformer。Visual Encoder 为 CoCa。可学习参数大约有 135M。
- 在 WebLI 数据集上,以 batch_size=2048 训练了 500K steps。Gumbel-softmax temperature 超参需要有比较复杂的 schedule 策略才能训收敛。
最终 De-Diffusion 的输出和重建效果类似于:

De-Diffusion 输出的长文本只包含文本和数字,不一定很通顺,但包含一些有意义的短语。把输出的 caption 送入不同文生图模型,能得到一些语义和原图很对应的结果。这个效果,让人怀疑是不是不同文生图模型都用了 OpenCLIP ViT-H。De-Diffusion 仿佛是一个 Encoder 版本的 CLIP Interrogator,输出结果肯定与 CLIP Text Encoder 强相关。
作者做了一些消融实验来验证自己的设计:
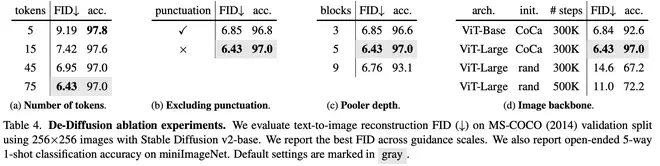
- 预测文本 tokens 数。发现 token 越多重建效果越好,但是用 caption +LLM 去做分类的结果则越来越差,可能是因为 caption 包含了更多图片细节的描述,图片主体的描述占比越来越低。
- 是否要删掉词表中的标点符号。删掉词表中的标点能让 De-Diffusion 的输出语义更丰富。
- AttentionPooler 如果太深了,容易过拟合到 Imagen 上,导致 SD 2 的重建效果变差。如果太浅了,则欠拟合。
- VisualEncoder 越强,结果越好。
有了 De-Diffusion 输出的 caption,构建类似于 Image context: <De-Diffusion Caption> <Question> 这样的 prompt,送入 LLM 就可以做一些 VQA 任务了。在一些指标上甚至能超过 Flamingo。作者报告的结果里有个有意思的现象,De-Diffusion 的 0-shot 效果并不领先,32-shot 反而超过能超过其它 MLLM 的 32-shot 结果。可能是因为 De-Diffusion 的输出都是词语短句拼贴,LLM 多看几个示例才能学会怎么从 De-Diffusion Caption 中提取关键信息。
总得来说,De-Diffusion 是个挺有趣的实验品,很有新意。其训练方法上和 DreamLLM、SEED-Tokenizer 等大思路一致,实现的效果类似于能一次前向出结果的 CLIP Interrogator。由于文本只能表达高级语义信息,很难用这样的方案去做现在其它 MLLM 已经能做到的对图片的局部理解(比如找到图片中某个物体)。另外由于训练时没有引入 LLM,导致用测试时用 LLM 去完成多模态问题时效果也没有那么好。
其实用性虽然不是特别大,但能有效地帮助人理解 MLLM。比如,现在用的是离散的真实文本,换成连续的 text embedding(就像 SEED-Tokenizer 了);现在只用了 Diffusion Loss,可不可以再加上 LLM 的 loss,同时预测 caption,进一步强化语义(就像 DreamLLM 了)。