
DiffBlender目标是能同时结合文本、图片、不带空间信息的token序列、带空间信息的token序列等多种不同模态的控制信号,通过高效地训练Adapter或者HyperNetwork之类的外挂组件,实现可扩展的多模态信号控制图片生成。
其主要对标的是Composer、ControlNet这一类的算法:
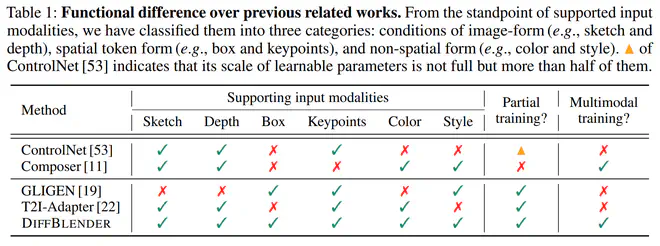
DiffBlender的核心就是设计哪些接口来接受不同模态的控制信号:
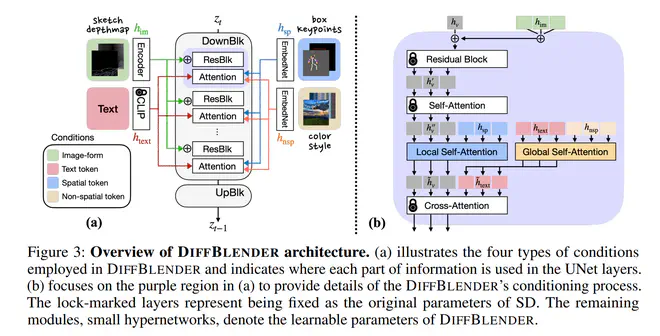
DiffBlender总是使用类似于Flamingo里面那种Gated Attention机制来融合token序列类型的控制信号。即在原有token序列上新加一个被\(tanh(\beta)\)“门控”的SelfAttention,\(\beta\)初始化为0,即训练最开始新增信号不起作用。
对于具有空间属性的token序列,GatedAttention被添加在UNet中的SelfAttention层的输出上:\(\widetilde{h}_v \gets h^{\prime\prime}_v + tanh(\beta_l)SelfAttention([h^{\prime\prime}_v, \{h_{sp,i}\}])[:V]\)。
对于如颜色、图片风格这样的全局token序列,GatedAttention被添加在文本特征上:\(\widetilde{h}_text \gets h_{text} + tanh(\beta_g)SelfAttention([h_{text}, \{h_{nsp,i}\}])[:L]\)。
总结一下,token序列类的condition信号都是通过作为CrossAttention层输入的残差传入网络的,但是包含空间信息的token是作为中间激活值的残差,不包含空间信息的token则是作为text embedding的残差。计算attention的对象分别是中间激活值和text embedding。
Embedder网络部分,image形式的condition就直接用8个ResNet Blocks+ZeroConv来提取不同层次的特征,其它token形式的condition则用3层FC的MLP。
这么多模态训练时怎么组合也挺麻烦。DiffBlender支持先训练一部分控制信号,再增加一些控制信号继续训练。当然,为了获得更好的效果,信息过多的condition应该靠后加。后面引入新condition时,可以把之前的condition信号置空。DiffBlender用全0tensor作为image格式的condition的空condition,用可学习零初始化的token作为token序列形式的空condition。图片格式控制信号的置空概率为0.5,其它信号置空概率为0.1。
在前向时,作者设计了一种只增加某个模态CFG的策略:就是在普通CFG的基础上,增加了一项有无某特定condition时分别对于的noise predition之差。比如有图片文本两个控制信号,传统的CFG就是一个用图片+文本都有时的噪声预测减图片文本都没有的噪声预测。DiffBlender则提出在此基础上在增加一项有图片有文本与有文本无图片时噪声预测之差的,就能进一步精细地调整图片的控制强度。
一些示例的控制效果如下:

论文链接:DiffBlender - Scalable and Composable Multimodal Text-to-Image Diffusion Models