
作者训练了一个基础的LDM,使用CLIP+T5做condition,2.8B的UNet。然后使用超高质量数据微调小于15K次迭代(batch_size=64)。这样得到的模型Emu在美观程度和语义匹配程度上都远超SDXL。作者在其它架构的文生图模型上也做了类似的finetune实验,证明了极高质量数据做STF确实能一下子提升模型美观程度,又不降语义能力。

- 增加VAE得到的latent的channel数,从4增加到16;
- 使用Fourier Feature Transform预处理图片,增加输入channel数,强化细节;
- 引入对抗损失,增加重建细节的能力。 经过这些优化,VAE重建ImageNet的PSNR从28涨到了34。
作者一直强调的超高质量图片的一些sample:

收集超高质量图片的流程:
- 去除有害图片、美学评分、OCR识别、CLIP Score等基础图文数据集清洗流水线;
- 根据图片的大小、比例筛除一部分数据;
- 使用 visual concept分类器调整不同视觉概念的图片占比,重点关注人像、食物、动物、风景等概念的图片。
- 根据图片自带的一些元数据,比如INS上图片的likes数量等,筛图片。至此剩余~200K张图片。
- 使用通用人工,优化recall,筛掉数据中一看就不怎么地的图片。
- 使用专业人力,优化precision,只保留在构图、光照、色彩、主题、故事性等等方面都满足摄影领域专业人士要求的图片。共收集~2K张图片,再人工标注得到每张图片的caption。
实验部分作者没有做任何自动化定量指标。全部都是用人去评判,做法是给两张图片A、B,带/不带文本,让人选择更贴合文本/更美观的图片。
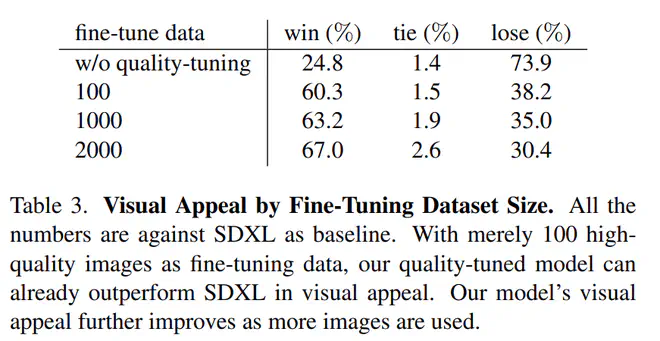
与SDXL的对比如下:
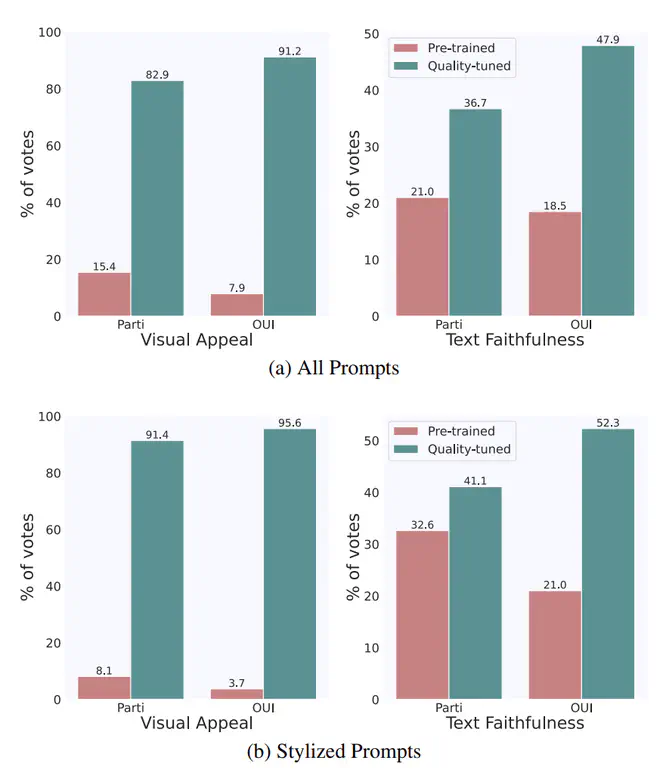
微调前后对比,改进也很明显:

论文链接:Emu - Enhancing Image Generation Models Using Photogenic Needles in a Haystack