
DALLE3的效果有多牛自不用说。OpenAI最终还是出了一篇简单的介绍DALLE3的论文,涉及到的模型细节很少,重点是讲如何构造训练数据。
OpenAI分三个阶段训练搞了一个基于CoCA的Captioner,用于标注数据:
- 用CLIP作为视觉embedding,在alt-text + image数据集上训练了一个CoCA模型;
- 在一个caption主要描述图片中的主要概念的数据集上微调CoCA,得到一个能生成“Short Synthetic Caption(SSC)”的Captioner。
- 在一个caption包含图片中主要概念,及其周围、背景、图片中的文字、风格、颜色等描述的数据集上第二次微调,这次模型能生成“Desciptive Synthetic Caption(DSC)”。
Alt-Text、SSC、DSC这三种不同的caption示例如下:

有了重新标注后的数据后,OpenAI做了一组消融实验去分析如何正确的使用标注数据。
他们透露出来的用于消融实验的算法细节有:
- 是一个T5-conditioned image diffusion模型,没有用自回归类型的生成模型;
- T5 XXL embedding通过CrossAttention(论文上提到的一个莫名的xfnet是什么?)送入UNet,timestep embedding通过控制GroupNorm的scale和bias送入UNet;
- T5做condition,预测VAE latents(32x32),得到256x256大小的图片;
- 每次消融训练500K step(batch size为2048,共1B样本);
- 启用了EMA;
训练时,隔一段step就用CLIP ViT-B/14计算下50Kprompt生成图片的图文相似度。
首先消融对比了一下不同caption类别的效果:
有三个不同的setting(为了防止过拟合到某种特定的合成caption模式,不利于日常测试使用,不同setting都加了5%的alt-text保证caption丰富性):
- 全部使用alt-text
- 95%短合成caption(SSC)+ 5% alt-text
- 95%长合成caption(DSC)+ 5% alt-text
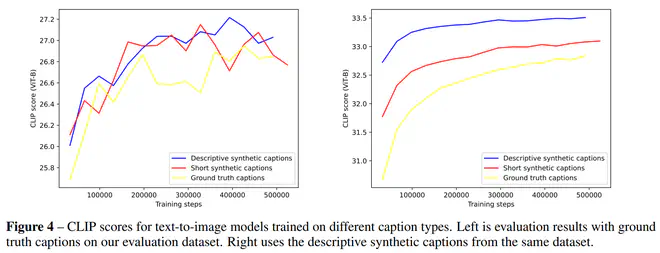
观察结果CLIP Score可以发现,无论用alt-text还是DSC去计算CLIP Score,使用合成caption的结果都好于不使用。如果用DSC衡量相似性,很明显能看到用DSC的效果持续优于其它。而用alt-text时,噪声太多,导致clip score也有些交叉。
他们也对比了一下用65%、80%、90%和95%的合成caption的效果,发现95%的持续高于其它比例。
以上就是DALLE3训练前的一些关于数据的消融探索实验。之后OpenAI用消融实验中的模型的**“scaled-up”,外加“several other improvements, many of which are not covered in this document”**版本训练了DALLE3。
除了这语焉不详的一句话以外,对于DALLE-E 3,OpenAI还透露:
- 使用了一个他们叫做caption upsampling的技术,即使用GPT4 rewrite用户指定的caption,但是论文中列的指令和之前twitter 微博上泄露的指令好像不一样。但总之,要用GPT4把用户输入的caption扩充为一段丰富描述的长文本。
- 使用VAE latents当作condition,训练了一个Diffusion Decoder。他们说这种Diffusion Decoder比VAE Decoder能生成更好的图片细节(比如人脸、文本)。
- 由于使用T5 text encoder,会把整个word转换成单个token,导致模型合成图片中的文本时会偶发缺字少字。可能用byT5这种没有tokenizer的模型当作encoder会更好一些?