
KOSMOS-G的目标是实现zero-shot personalized text to image。能够实现多Object组合文本的保ID生成。
KOSMOS-G的训练流程分为三个阶段:
- Multimodal Language Modeling:实际上就是KOSMOS-1。图片经过CLIP Image Encoder+Resampler变成Visual Token,和文本token一起,从头训练了一个LLM。这个阶段的主要目标是有一个接受图片和文本混合输入的LLM。理论上用LLaVA之类的网络应该也可以?
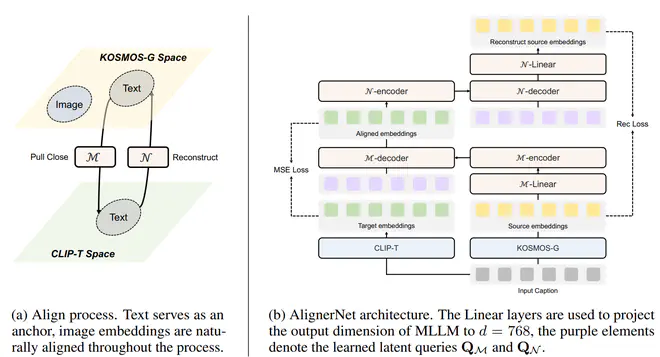
- Image Decoder Aligning:这个阶段目标是让KOSMOS-1能输出与Stable Diffusion中UNet的CrossAttention输入对齐的embedding。Kosmos—G这一阶段的策略比较Naive,只使用了文本数据,要求经过AlignerNet处理的MLLM输出特征与文本的CLIP Text Embedding对齐。
- Instruction Tuning:这个阶段就是混合caption及caption中名词对应的图片区域像素一起作为MLLM的输入,得到送入UNet后能重建原图的embedding。即组合caption与caption中名词对应区域的像素一起重建原图。
第一阶段只训练MLLM;第二阶段固定MLLM,只训练AlignerNet;第三阶段MLLM和AlignerNet一起组合训练。
第一阶段可以理解成从头训练的LLaVA或者miniGPT4,不再详说。
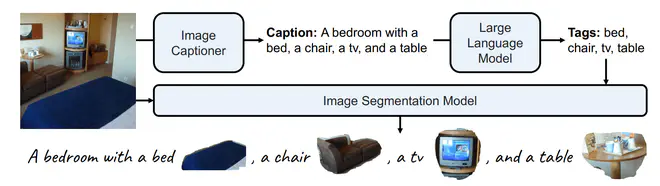
A bedroom with a bed <image>bed-image-embedding</image>, a chari <image>chair-image-embedding</image>...,然后送入AlignerNet里面得到embedding,送入UNet。用重建原图的Diffusion Loss优化MLLM和AlingnerNet。训练时也混合了一些InstructPix2Pix的编辑任务数据和文生图训练数据。
第一阶段训练数据同KOSMOS-1一致(估计就是拿预训练的KOSMOS-1当第一阶段模型继续训练的)。第二阶段只用了图文pair对数据里的caption。第三阶段则用了使用OpenImageV7构造的数据集:用BLIP2 OPT6.7B给OpenImageV7数据打caption,然后用MPT-7B-Instruct提取caption中的tag,然后用CLIPSeg提取每个tag对应的区域的mask图。第三阶段Seg构造数据:InstructPix2Pix数据:text2image数据比例大概是2:2:1
KOSMOS-G能实现很多之前方案甚至做不了的效果:

因为KOSMOS-1是开源的,感觉可以组合KOSMOS-1与IP-Adapter复现一下他这个效果:
- 第一阶段给KOSMOS-1的输出接一个Mapping网络,直接当作IP-Adapter的condition,用Diffusion Loss优化Mapping网络重建图片。这一阶段的输入是图片的caption(可以用与送入CLIP Text Encoder不同的长caption?),送入KOSMOS-1,其输出作为mapping网络的输入。
- 之后就可以同上面的第三阶段一样训练了。
用IP-Adapter这样的机制不需要网络专门去与CLIP Text Embedding对齐。这里的第一步对齐训练完成后得到的东西可能就能提升SD的图文匹配能力,就已经足够有用了。
论文链接:Kosmos-G - Generating Images in Context with Multimodal Large Language Models