
ParaDiffusion 尝试解决paragraph-to-image generation任务,即给定一个长达 400 词甚至更多的 prompt,生成对应的图片。 T2I 模型要先能理解这么长的图片描述,然后把描述中涉及的关键物体都以一个合理的方式展示在图片中,难度很大。ParaDiffusion 认为之前的文生图模型做不了这样的任务既有数据上的原因,也有架构上的原因。之前的文生图模型基本上是基于 alt-text(平均甚至只有11 词)训练的,图片 caption 信息太少;提取文本 embedding 的网络要么是只接受 77token 的 CLIP,要么是只接受 128token 的 T5 Encoder。因此,ParaDiffusion 用 CogVLM 标注了4M LAION 子集,人工标注了600K 高质量图片,构建了两个 caption 长达 400 词的高质量数据集;使用 LLaMA 2 作为 text encoder。
ParaDiffusion 的思路很直接,文生图社区的人估计都能想到,简单地想法没有被迅速实现,一定是有些阻碍的。我们主要看他是怎么回答以下几个问题的:
- 怎么收集构建长文本描述-图片的数据?要保证描述丰富多样且没有错误,贴合图片。
- 用最新最牛的 LLM 很自然,但最近的 LLM 基本都是 decoder-only 结构,这种结构的 LLM 提取的 embedding 适合文生图任务吗?
- 其实即使是短 prompt,现在的文生图模型的图文对应性都很差。换成长 prompt,更难对应了。有什么特殊的手段可以强化图文对应性?
先大概过一下 ParaDiffusion。
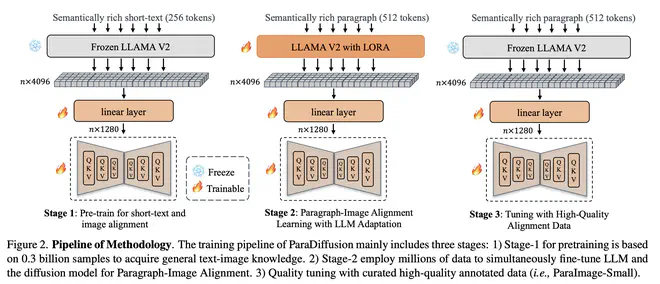
ParaDiffusion 的训练分 3 步走:
- 预训练:这个阶段除了把 text encoder 换成 LLaMA 2 外,都和 Stable Diffusion类似。在 100 M 的 LAION 子集+200 M 的内部数据上,用 56 张 A 100,训练 1.3 B 的 UNet 模型,持续了 5 天。训练过程中分辨率从 256 增加到 512。
- 长文本描述-图片对齐训练:作者认为直接用 LLaMA 这种 decoder-only 结构的 LLM ,没有对图片的理解,embedding 是否合适也是未知。所以在 long caption 数据集上训练时,给 LLaMA 2 加上了 LoRA,也和 UNet 一起被训练。这一过程使用了 CogVLM 标注的合成 long caption,56 张 A 100 训练了 2 天。
- 高质量数据微调:类似于 Emu,ParaDiffusion 最后也用了少量人工选择,人工标注的高质量数据做了一下微调,过拟合一下高质量图片。这一阶段是固定 text encoder 的,只微调 UNet。
ParaDiffusion 使用的 long caption 数据分为两部分,ParaImage-Big 是生成的。
| 数据名称 | 图片来源 | long caption 来源 | 描述 |
|---|---|---|---|
| ParaImage-Big | LAION-Aesthetics 中短边大于 512 的图片,3.2 M;SAM 数据集(2 M)中没有马赛克的图片,约 100 K | CogVLM 标注 | MLLM 标注 caption,可能有幻觉。70%的图片 caption 超过 100 词 |
| ParaImage-Small | 从 650K 张 LAION-Aesthetics 中选中的 3K 高质量图片 | 人工标注图片中的对象,对象属性,对象关系 | 描述不少于 50,不多于 500 词。3K 图片用了 20 个标注,标注审核一共花了俩星期 |
最近需要标注 long caption 的好几篇文章都用了 SAM 数据集,因为 SAM 数据集是用于做分割的,图里面细碎的小物体比较多,图片复杂度高,适合也需要长文本去描述。
这两个数据集里的sample大概长这样:

不得不吐槽的是,ParaDiffusion 这篇论文感觉没有被校对过,一会儿说 56 张 A100,一会说 56 张 V100;一会儿说 LAION,一会儿又有 SAM 了。论文小 typo 也不少,真当写论文是我写博客呢呀😒。
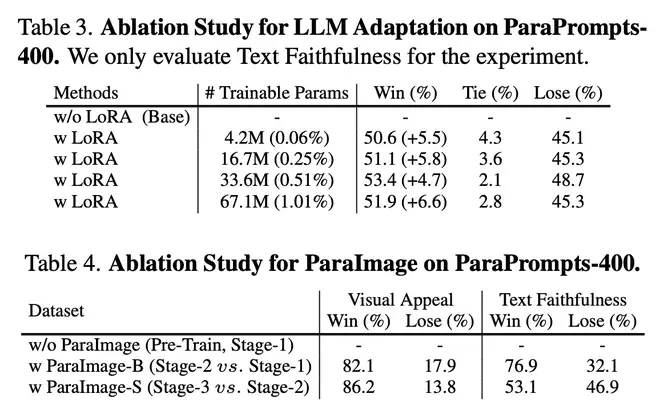
作者在 Table3 中对比了第二阶段不用 LoRA 微调 LLaMA 和不同 LoRA 参数的结果,微调 LLaMA 的参数从无到有,从小到大,都能持续提升性能。
在 Table4 中,经过二阶段对齐训练后,图文对应能力迅速提升;三阶段训练则对图文对应能力贡献不大,主要是提升了图片美观程度。

ParaDiffusion 主要是给社区展示了 long caption 文生图模型的可行性。text encoder 用 LLaMA,图片用 CogVLM 标注,decoder-only 的 LLM 微调一下更好用,这些策略 or 结论都比较自然,容易接受。虽然刚刚批评 ParaDiffusion 论文一堆 typo,但考虑到 CogVLM 10 月初才开源,又要标数据,又要从头训练模型,然后11 月 24 号就能把论文挂 arxiv,不得不赞扬作者行动力太强,卡也多,服气。
但是 ParaDiffusion 没有回答本文开头提的第三个问题。提升文生图模型的图文对应能力,仅仅靠数据就够了吗?短文本对应性都不足,长文本直接堆数据,不改进算法,靠大力出奇迹,上限有多高呢?
论文链接:Paragraph-to-Image Generation with Information-Enriched Diffusion Model