
这篇论文把训练过程拆分成了3个阶段:
-
Capturing Pixel Dependency:这个阶段模型进行类指导的图片生成,目标是能生成合理的图片。这个阶段模型在ImageNet上预训练了一个class guided的图片生成模型。然后用这个模型当做预训练权重,接着后续的训练。(估计就是直接挑选了一个模型,懒得从头训练了)
-
Text-image alignment learning:这个阶段进行基础的文生图训练。为了能实现准确的图文对应,作者用多模态大模型标注数据构建了一个caption中名词非常多,即描述非常丰富的图文数据集。然后用这个训练模型。
-
High-resolution and aesthetic image generation:这个阶段使用高质量的图文数据finetune一下模型。提升生成图片美学质量。这个阶段的设置感觉和Emu那篇文生图论文的思路很像。
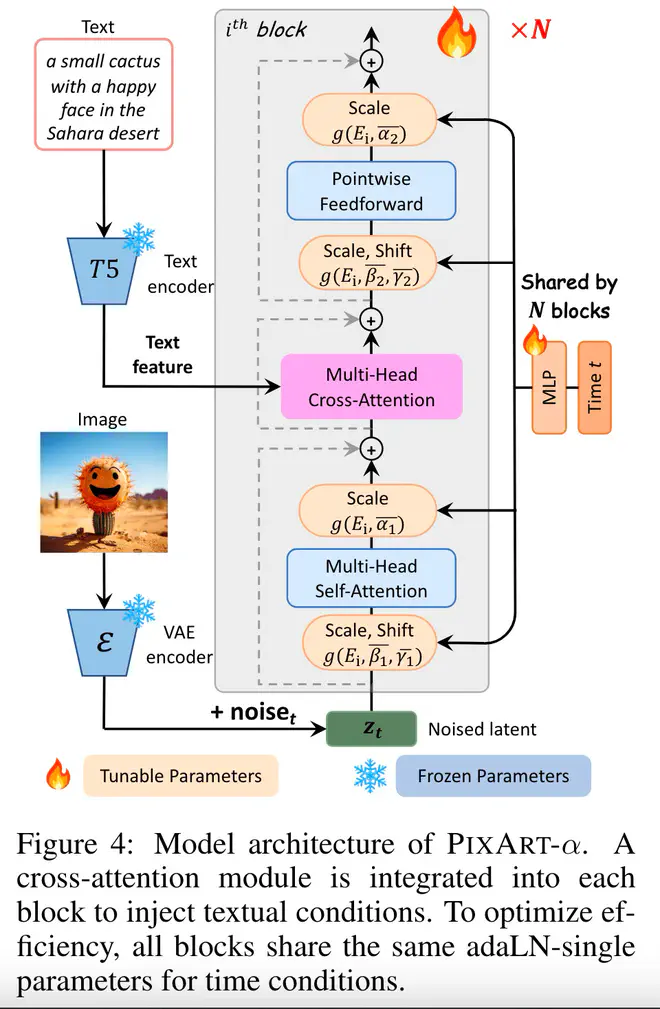
这篇论文提出的方案里面,最关键的有两大部分,一是模型怎么设计。比如怎么把一个类别做condition的预训练模型转换为文生图模型。另外一个是数据怎么构建。
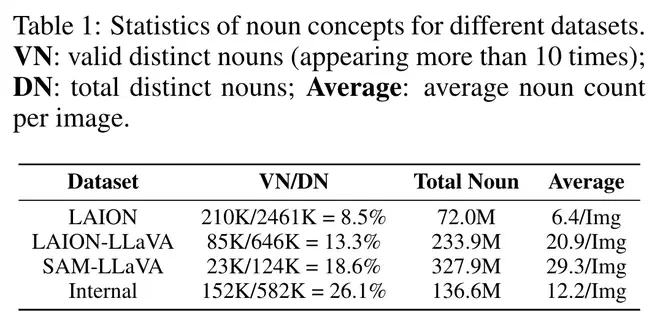
作者觉得目前的LAION数据集的原始caption标注太差了。为此,用LLaVA标注了LAION数据集和SAM数据集构建了一些新数据。LAION数据集中商品图很多,图片中没有很复杂的Object直接的关系,为此,作者专门标注了SAM数据集,觉得这个用于分割的数据集中包含更多的Object。用LLaVA标注后,LAION的每张图片平均名词从6.4增加到了20.9个。
但是多模态LLM天生有的幻觉问题感觉很难解决呀?这点比较好奇,纠结要带noisy的web caption,还是要丰富且一致,但有幻觉的生成caption?之前同事对比了使用OFA标注的caption与web caption,发现还是web caption结果更好一些。现在换成了LLaVA,会好很多吗?
论文链接:PixArt-alpha - Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis