
SUPIR (Scaling-UP Image Restoration) 目标是基于预训练的文生图模型先验,20M 高质量图片数据, MLLM captioner 等技术,实现一个 scaling-up 的图片复原网络。
SUPIR 训练时,整体的大思路是用高质量图片与其对应的降质图片形成 pair 对,降质图片对应的 MLLM 合成 caption 作为文本控制信号。这里的“降质”复用了王鑫涛的 RealESRGAN 中提出的模拟真实低质量图片的降质策略。
要做到 Scaling-UP,首先数据要 Scaling-UP。SUPIR 作者吐槽之前图片复原领域常用的 DIV2K 之类的数据集太小,SA-1B、LAION 这样的数据集噪声太多,所以他们自己收集了 20M 的1024 x 1024, high-quality, texture-rich, and content clear的图片,混合 FFHQ in the wild 提供的一共 70K 人脸相关的数据。这些数据作为正向样本,即期望模型能把低质量的图片恢复成这些数据的清晰度。假设训练 SUPIR 时,FFHQ 的质量已经算是达到了质量要求,那收集 20M 的同质量的数据没有想象地难。但是如果 FFHQ 质量其实不够,只是因为 70K 量级相对于 20M 可以忽略。那如何收集这 20M 足够质量的数据,可能本身就是个问题 😈。作者除了正向的样本,还收集了 100K SDXL 的生成图作为负向样本。这里的负向样本,需要和前面提到的正向图片的降质结果区分开来:负向样本训练时作为模型的输出,降质图片训练时作为模型的输入。负向样本及其降质结果,构成一个负向 pair 对。而降质结果和正向图片对应,也形成一个个正向 pair 对。上面收集的所有数据,作者都使用 LLaVA 标注了足够详细的 caption。
算法 Pipeline 上,SUPIR 看起来很像是 SDXL+ControlNet 的一些改进:
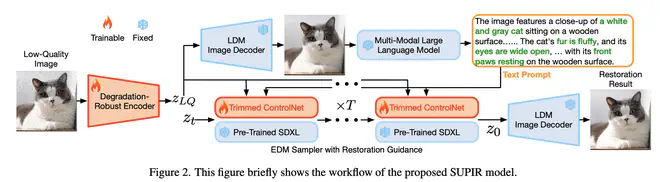
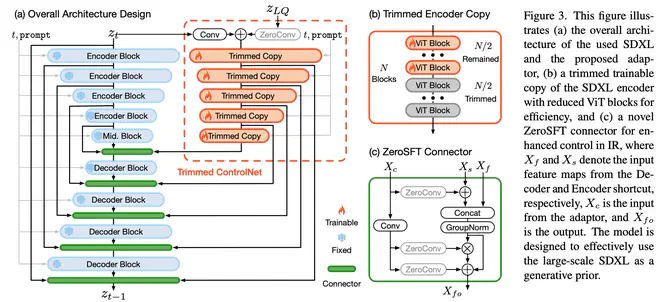
- ControlNet 中使用一个随机初始化的 CNN 将输入 condition 8 倍降采样以匹配 VAE Latent 的尺寸。SUPIR 则使用 Degradation-Robust Encoder 编码图片到一个近似 VAE latent 的空间。不直接用 VAE Encoder 的原因是 VAE 训练时没见过太多低质量的图片,直接使用 VAE Encoder 容易合成图片出现一些伪影。为此,SUPIR 使用 LQ-HQ 数据,固定 VAE Decoder,微调 VAE Encoder ,得到了一个对输入图片降质更不敏感的 Degradation-Robust Encoder。
- ControlNet 训练时依然使用 alt-text,作者这里用 VAE Decoder 解码 Degradation-Robust Encoder 得到的 latents,得到一张噪声不那么严重的图片。送入 MLLM 得到其对应的标注更密集准确的 caption。只有在测试推理时,才需要在线得到 caption。训练数据集已经提前标注过了合成 caption。
- 由于 SDXL 有 2.6 B 参数,如果依然拿完整的 SDXL UNet Encoder 作为 ControlNet 初始化,总的可训练参数有 1.3 B 以上,训练成本过高。作者裁剪掉了 SDXL UNet Encoder 中每个分辨率中的一半 ViT Blocks,将总的可训练参数降到了 600 M。加速收敛,减少对训练数据量的依赖。
- ControlNet 的实现中,ControlNet 的输出直接作为残差,与对应位置的特征相加进行融合。作者认为这样的融合方式控制力不够强。设计了一个叫 ZeroSFT 的结构,可以看作在原来的 ControlNet 融合方式得到的结果之后,又增加了 GroupNorm 与 spatial feature transfer 结构,ControlNet 输出直接调整融合特征的均值方差,以此增加 ControlNet 特征的控制力。
- 如果训练时只使用高质量的图片,MLLM 的合成 caption 中一般也不包含对图片质量好以及坏的评价,那么模型可能缺乏对负向词,负向图片的理解。就不能和之前使用 ControlNet 一样,在测试时指定 Negative prompt,在 Negative Prompt 中写“low quality, deformation, low resolution”这类词。为此,作者除了 20 M 以上的正向样本,还引入了 10 K 负向样本。比例大于 2000:1。作者使用 SDXL 的合成图片+Negative Prompt 作为负向样本。这样,测试时,SUPIR 可以在做 CFG 时,使用 Negative Prompt 来进一步提升合成质量。
- 作者也提出了一个推理时的改进点,在不同 step 以不同权重将预测 latent 与低质量图片对应的 latent 进行插值融合。感觉这点改进像是一个软化版的 img 2 img,在噪声很强的阶段,大量采用低质量图片中的低频细节,有助于维持生成图片和输入图片的语义一致性。
作者在训练时,把图片 crop 成了 512 x 512 的 patch,以 1e-5 的学习率,在 64 卡 A6000上训练大约 10 天。
作者对比了 SUPIR 和之前的基于 GAN、基于 SD 的方法。在 PSNR、LPIPS 之类的有参考图的指标上,没有超过 PASD、BSRGAN 等网络,但在 MUSIQ 等无参考图的指标上,远超之前的方法。作者观察认为 SUPIR 的生成图生成细节更多,效果更合理,导致和原图相比 PSNR 这类指标反而下降了。


作者对比了 ControlNet 的残差融合策略与 ZeroSFT 融合策略。在定量指标上,发现残差融合的方式无参考图指标更好,ZeroSFT 的融合方式有参考图指标更好。作者认为这是因为 ZeroSFT 能更好地保证 LQ 图对生成结果的控制能力。残差融合策略结果生成成分更重,更容易出现生成细节。当生成细节过多时,生成结果也可能不会太好,比如下面的定性对比,ControlNet 原始融合方式的结果生成痕迹很重, 很多伪影细节。

作者也给了不同量级的数据集上用他们的方法训练结果的对比,可以明显看到,当量级 Scaling UP 到 20 M 之后,合成图片细节合理了很多。

SUPIR 已经开源了前向代码,模型可能很快也会开源。论文贴出的 demo 效果也很惊人。看论文过程中也有了一些问题。不知道有没有机会向作者提问。
- 训练时,将 1024 x 1024 的图片拆分为多个 patch,那么每个 patch 的内容已经和 MLLM 标注的 caption 不完全匹配了。这个问题怎么克服?
- 论文说训练细节时强调需要将原图 crop 成 512x 512 的 patch,但推理部分又没有说如何将多个 patch 的恢复结果进行融合,看起来像是直接输出的 1024 级别的清晰图片。这里的细节我没理明白。
- 训练时还需要以一定概率将 caption 设置为空吗?如果需要,是否有些技巧呢?比如负向样本的 caption 不需要被 drop,只 drop 正向样本的 caption。这样负向样本与负向 caption 严格对应绑定,空文本能与高质量数据对应起来。