有趣的论文#
MaskGIT: Masked Generative Image Transformer#
Google新的文生图大模型Muse所依赖的生成模型。介绍了一种新的"Masked Visual Token Modeling"训练策略。
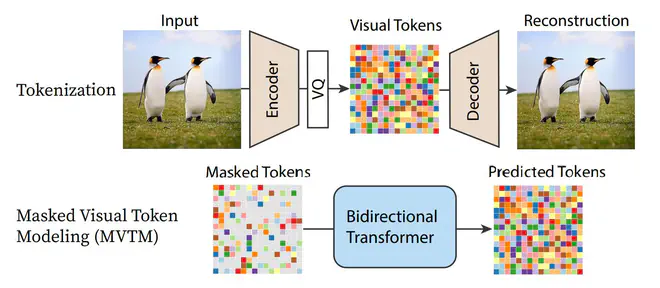
这种生成模型依赖一个预训练好的VQGAN,能将图片tokenization成一组量化后的token。VQGAN编码图片得到的token是离散的,所有可能的token构成一个codebook,假设其中包含K个token选项。MVTM训练就是指给定masked tokens,让网络预测这些被masked掉的token。对于每个被masked掉的token,网络给出一个K维向量预测当前token属于codebook中每个token的可能性,类似于完成一个K分类任务。
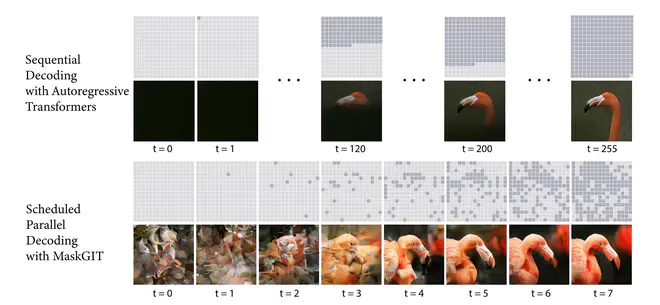
在测试时,与之前SOTA使用自回归的方法,逐行再逐列依次生成token不同,MaskGIT每次迭代从一组masked tokens预测出每个位置token可能的选项,然后仅保留那些置信度足够高的位置的token,然后继续将当前预测结果再送入网络进行下一轮预测,直到所有token都被预测出来。与之前常用的自回归方法不同,每轮预测都是基于对图片的全局感知,可以并行预测。这样网络仅需8次前向就能生成高质量的图片。
整个训练和测试过程中,每次迭代有多大比例的token被mask掉是一个非常关键的参数,即mask radio的scheduler。作者实验对比了多种简单的scheduler策略:

发现cosine的效果最好。另外凹函数的FID普遍低于凸函数。作者声称这是因为在图片token比较少的时候,即t接近于0时,最好少预测一些token,因为此时不确定的太多;而t接近于T时,因为大部分token都已经存在了,这时可以多预测一些token,加速收敛。另外,作者发现T也不能太大,因为这样会导致每次只保留了所有预测的token中最具确定性的token,降低了整个合成的多样性。
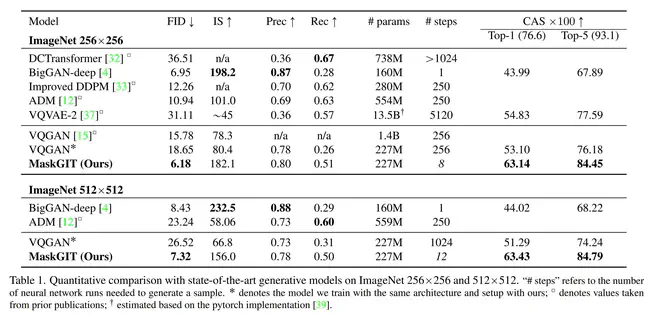
最终MaskGIT与其它SOTA方法对比,效果更好,所需的前向step数也明显少。
Muse: Text-To-Image Generation via Masked Generative Transformers#
Google 的新文生图大模型,没有使用文生图领域常用的Diffusion或Autoregressive模型,而是使用作者之前提出的MaskGIT作为最底层的生成模型。论文摘要里着重强调了Muse模型的高效。
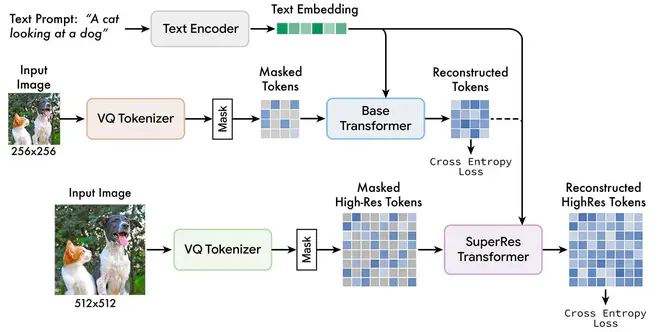
Muse分为两个阶段:先用Base Transfomer,受T5的text embedding控制,实现256x256图片对应的tokens的生成,然后这些tokens融合T5的text embedding,送入SuperRes Transfomer的cross attention层实现对512x512的对应tokens的生成。之后送入VQGAN的Decoder得到图片。这其中的Base Transfomer和SuperRes Transfomer都是基于一作之前搞的MaskGIT,每次都是给定一组mask掉部分区域的tokens,预测当前位置的token应该是codebook中的哪个token,类似于分类任务(所以训练的时候可以直接用Cross Entropy Loss)。
Muse的超分阶段一个没想到的设计是,将Low-Res Tokens和Text Embedding经过一些网络变换后concat一起送入cross-attention。Stable Diffusion在类似的场景下选择的是将二维embedding和网络输入一起concat,Muse这么做直觉上的坏处是丢失了Low-Res Tokens中的位置先验,但信息交互会更有效一点,所以Position Embedding估计是必不可少了。
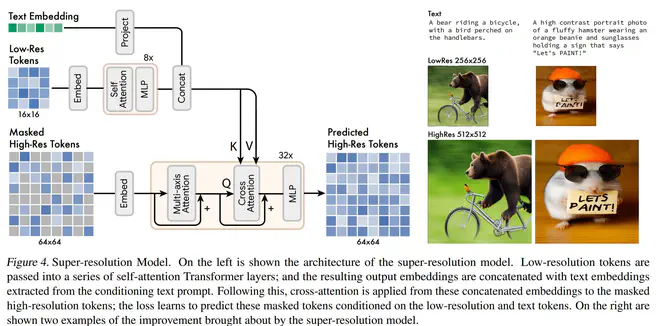
Muse为了也用上Classifier Free Guidance,训练的时候也会以10%的概率将text置空,然后测试的时候用conditional预测出的logit值和unconditional预测的logit值计算一个移动方向,很接近于CFG在Diffusion里面的做法。CFG这种策略总是感觉有点没想明白,但效果就是好,Muse这种非Diffusion的模型也主动拿过来用。
Muse复用了Imagen训练数据集,460M image-text pairs。值得学习的一个小训练技巧是,他们以0.7的decay factor,离线拿每5k steps存的checkpoint做EMA。这个EMA offline又避免了训练时EMA占显存还耗时,同时享受了EMA训练稳定的好处。
论文里cherry pick的图质量还是可以的,也能写字。不过我用我们训练的模型测试了一下,除了写字的比不上Muse,其它的挑一挑还是能比得上的。

和其它论文的比较Muse花的笔墨不多,感觉不是很充分。Muse和Imagen、Parti比生成速度,和Stable Diffusion比人工评测质量,有点鸡贼?

当然,因为其"Masked Visual Token Modeling"训练策略,Muse很适合做Inpainting这样的图片编辑任务:mask掉区域的token替换成[MASK],让网络预测即可,就这么训练的网络!
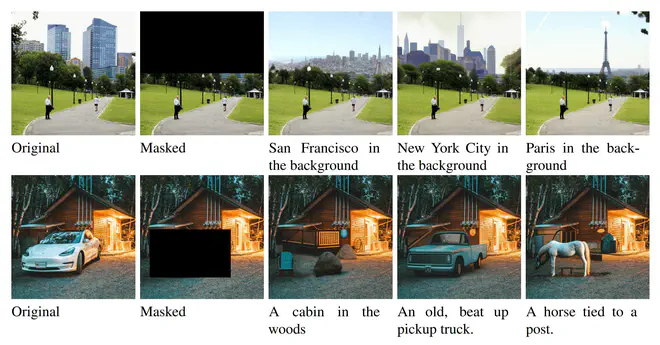
我记得Google是有一个比VQGAN更强大的Image Tokenizer模型的,Muse论文也提到了:
We use VQGAN rather than ViT-VQGAN as we found it to perform better for our model, noting that a better performing tokenization model does not always translate to a better performing text-to-image model.
这就有点离谱了,它也没解释为啥。论文附录里也提到他们也finetune了VQGAN的Decoder,让Decoder加残差,变深。效果也挺明显:

但为啥ViT-VQGAN比不上VQGAN呢?
Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces#
Paella这个模型提出的很早,之前一直没细看。最近有人说Muse的思路和Paella很像,就翻出来重新再看一下。
Paella和Muse大思路很接近,都是基于MaskGIT的"MVTM"思路来实现VQGAN Encoder得到的tokens生成,然后送入VQGAN Decoder得到图片。
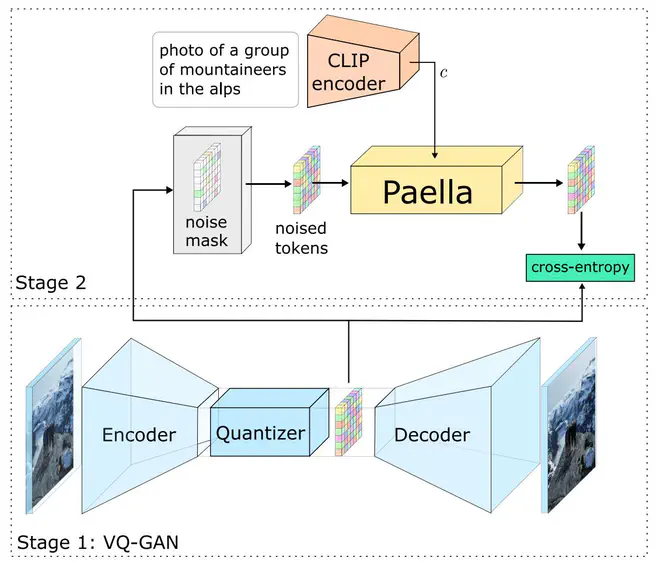
不过,Paella主体仅包含一个阶段,直接实现text->image的生成。同时,Paella主体使用了一个CNN网络,condition通过CNN网络中的modulated
LayerNorm注入网络。
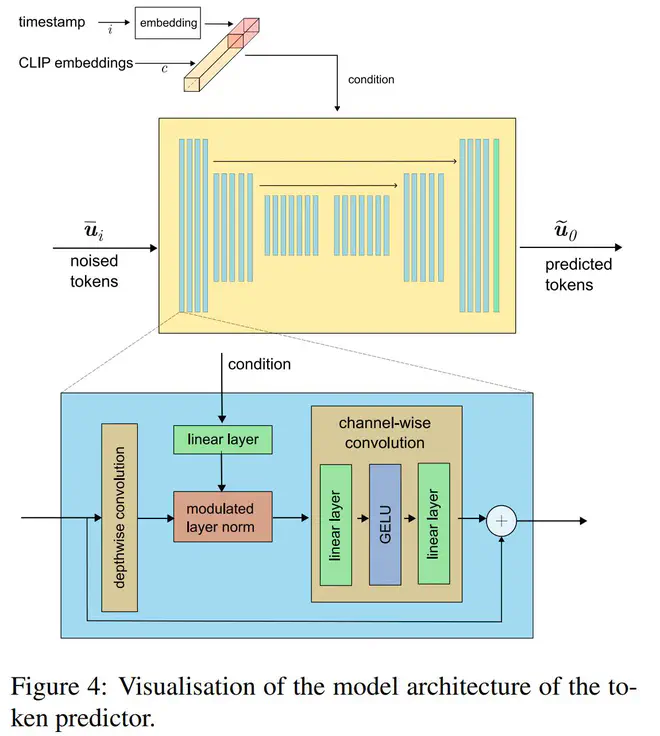
不同的是,Paella认为,MaskGIT每次预测时都预测剩余token中的一部分,没有重新refine网络早期预测的tokens的机会。所以Paella将MaskGIT的mask操作替换为noise,即网络的输入不是masked tokens,而是noised tokens。这里的noise不是指给token加一定高斯噪声或者什么,而是指随机将当前token替换为codebook中的其它token。Paella每次迭代时,都是从noised tokens预测一个noise更少的image tokens。
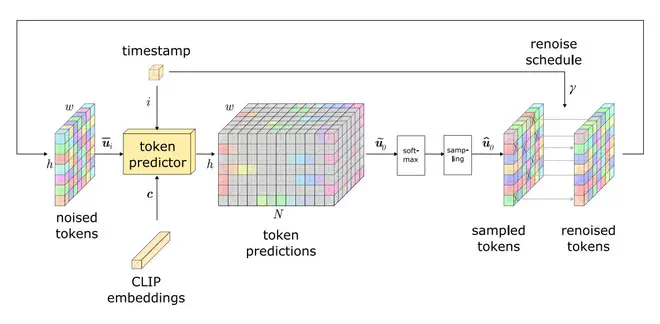
如上图,将noised tokens和condition送入Paella,预测得到w*h个N分类问题的logit值,之后采样得到当前轮的image tokens,之后再重新以一定概率,替换其中一些tokens。
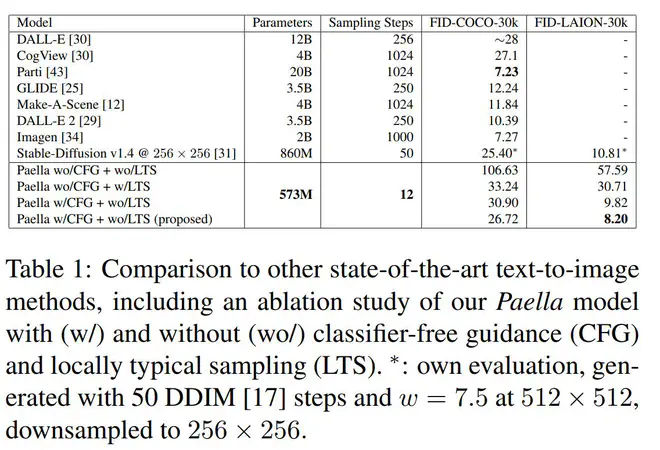
Paella在评测上新介绍了一个LAION-30K数据集,认为这样的数据集更多样,更丰富,包含我们更关注的艺术画等等。

实际上感觉Paella在COCO上的分数不是很高。生成图片的质量也不是特别好。从结果来看,肯定是比不上Muse的。但是这里不一定是论文提出的noise tokens策略不行,毕竟Muse使用了Imagen的数据集,数据集强于Paella使用的LAION,同时,Muse分两个阶段,降低了每个阶段的学习难度,可能也更合理。
有趣的说法#
Latent Video Diffusion Models for High-Fidelity Video Generation with Arbitrary Lengths argue LDM使用的KL-reg有问题:
For KL regularization, LDM rescales the latent by an estimated scale factor before performing diffusion model training, which, however, is vulnerable and has a great effect on generation performance. Imperfect scale factors could lead to implausible generation and bright spot artifacts when conducting experiments with different attention blocks
论文分析说这个的原因是:
a slight KL-regularization is not enough to reduce the variance of the latent space, and high-variance and centershifted latent distribution harms the generation ability of diffusion models.
所以他们直接抛弃掉了KL-reg,训练了一个纯粹的AutoEncoder,然后训练Diffsuion前提前统计AutoEncoder中间隐编码的均值标准差,然后对隐编码减均值除标准差做Normalization。
感觉他们论文里放的bright spot案例挺奇怪的,Stable Diffusion从来没出过类似的问题啊。不过统计latent的mean、std再归一化这个操作本身是更合理的,现在Stable Diffusion直接假设latent的均值为0了,所以只用std去归一化,不大合理。
Rethinking the Objectives of Vector-Quantized Tokenizers for Image Synthesis 提出了一个好问题:VQGAN的重建能力的提升,是否意味着基于预测VQGAN的tokens的生成网络的能力的提升?类似于一个我一直很关注的问题,LDM模型里面,现有的VAE的latent足够好了吗?这篇论文给的结论是需要同时关注VQGAN的语义压缩能力和重建图片细节保持能力。为此,他们提了一个很简单的改进方法:训练分为两个阶段,第一个阶段encoder和decoder同时训练,对网络重建图片的约束更倾向于语义一致,比如VGG网络的高层特征一致性做约束。第二个阶段则固定encoder,只finetune decoder,这一阶段则努力提升decoder重建原图细节的能力,用VGG网络的底层特征一致性做约束。
这个方法思路感觉很符合直觉,但在LAION这种大规模数据集上还用在ImageNet上预训练的VGG网络,估计不太行,我们用的时候可以换成CLIP?CLIP的高层次语义提取能力一定是很强的,但不知道网络前几层对low-level details的提取能力咋样。前两天看过一个微软蒸馏相关的文章TinyMIM,提出蒸馏的时候可以考虑去蒸馏self-attention中QK的乘积,V的自相关性等等,感觉这里也可以借鉴一下,用这些构造loss,去约束网络重建low-level details。
随便看看#
一些链接#
-
Maximum Diffusion - a Hugging Face Space by Omnibus 一个能同时测试同一个prompt在最新不同finetune模型上效果的demo。罗列了很多最新的finetune模型。
-
The Annotated Diffusion Model HuggingFace 的一篇关于从头实现Diffusion模型的博客,代码实现和讲解放在一起,看起来很清晰。
-
Comparing Captioning Models - a Hugging Face Space by nielsr 一个能同时测试GIT和BLIP不同size的模型的caption能力的demo。可以快速地给图片生成一个合理的描述。看上去BLIP-large不错。
-
Civitai | Stable Diffusion models, embeddings, hypernetworks and more 类似于leixa.art,但是汇集了不同SD的finetune模型和embedding等等。
新开源的finetune模型#

aipicasso/cool-japan-diffusion-2-1-0

dreamlike-art/dreamlike-photoreal-2.0
