论文#
Mid-U Guidance: Fast Classifier Guidance for Latent Diffusion Models#
Sketch-Guided Text-to-Image Diffusion Models#
虽然目前SOTA的Text2Image模型主要都使用CFG(Classifier Free Guidance),但是Classifier Guidance本身其实能提供更为Flexible的Guidance,毕竟Classifier其实可以是预训练的任何能提供梯度的网络,能构造一个loss就可以了。但是用Classifier做Guidance天然地存在两个问题:
- Classifier经常是在图片上预训练的,想复用这个预训练网络,需要首先得到图片。但现在常用的Text2Image得到最终的图片通常经过好几个阶段,比如DALLE2是CLIP Text Embedding -> CLIP Image Embedding -> Image,Stable Diffusion则是先得到VAE latent,送入VAE Decoder才能得到图片。这样导致Glassifier Guidance特别慢,甚至不可实现(比如DALLE2)。下图就是一个Stable Diffusion网络利用图片上预训练的Score Model(比如美学评分网络),实现Classifier Guidance的流程图。
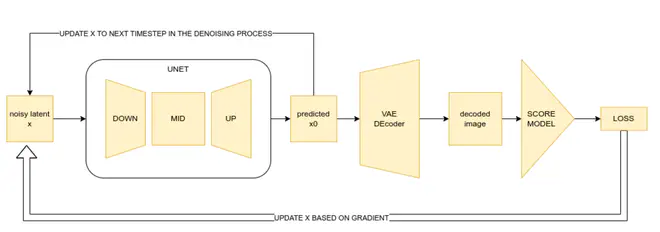
- Diffusion过程中,每个step能得到的结果所处的分布(尤其是Diffusion中靠前的step)和训练Classifier时所使用的分布并不一致,导致Classifier这个网络所提供的梯度不准。
Sketch Guidance 这篇论文和Mid-U Guidance这篇博文在解决不同问题时,都想到了借助Classifier Guidance。Sketch Guidance这篇论文的目标是利用Classifier Guidance约束生成图片的与参考Edge图一致,而Mid-U Guidance则是想约束生成图片的美学评分尽量高。这两篇文章面临上述的这两个问题时,提出了一套相同的解决方案,殊途同归。就放一起分享了。
这两篇文章提出可以利用Diffusion所使用的预测网络的中间特征及其对应图片的标注训练另外一个小网络。在Diffusion过程中,将每一步预测网络的中间特征送入训练的小网络,计算得到梯度,当作Diffusion预测latent的移动方向。
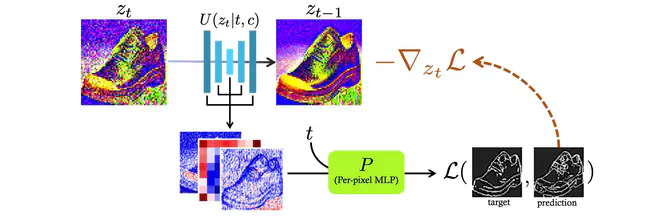
Sketch Guidance用一个Per-Pixel MLP(就是堆叠的Conv1x1吧...),处理堆叠的UNet中间层特征,得到Edge图,与参考Edge图计算一个loss,提供当前预测的\(z_{t-1}\)移动方向。
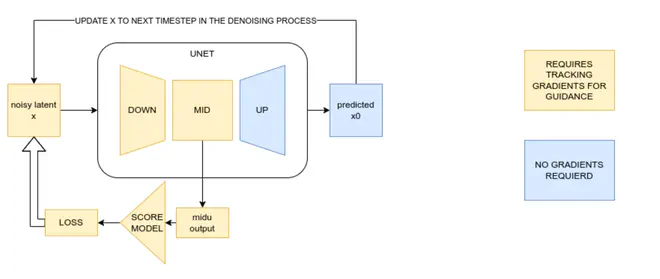
Mid-U Guidance也类似,拿UNet中间block的输出当做小网络的输入,计算出latent要移动的方向。
小网络计算梯度很快,同时只需要UNet网络的中间特征(甚至只是一部分特征),跳过了把预测的latent变成图片的过程。所以这种设计极大地克服了Classifier Guidance面临的第一个问题。至于Classifier Guidance面临的第二个问题:不同t的时候分布不一致,也挺好解决:训练特征->标注的小网络时,就保证网络见过不同t时对应的特征即可。
如下图所示,训练Sketch Guidance所需的Per-pixel MLP时,首先用VAE Encoder编码图片,然后采样不同t,按照DDPM的规矩加噪声,送入UNet网络得到中间特征,拿这些中间特征和原图对应的标注训练Per-pixel MLP即可。
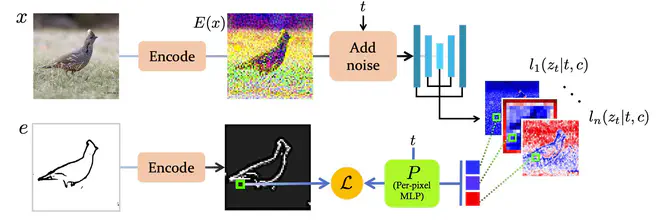
至于Mid-U Guidance,训练小网络的思路也完全一样,拿UNet中间特征和对应图片的美学评分训练小网络即可。UNet的中间特征即包含输入latent的信息,又包含CFG所使用condition、t等信息,理论上是包含足够训练小网络的信息了。
这两篇文章各自的效果也挺不错的,比如下面,使用Mid-U Guidance后,同意的prompt,生成图从左变成了右边。确实美了不少。可以在 Mid-U Guidance Sample Results查看更多结果。

Sketch-Guidance的效果如下,生成图片轮廓和参考Sketch基本一致。

这两篇文章本质上是提出了一种改进T2I大模型场景下Classifier Guidance的方法,后面我们收集一些奇怪的图片以及标注数据集,就可以训练一个小网络,不需要训练,在模型前向时约束模型图片的生成方向。
只言片语#
Stable Diffusion背后的CEO又提到一个新概念,他们正在蒸馏SD,蒸馏得到的网络具有很强的Zero-Shot能力,甚至使得finetune没有意义 “The newer models zero shot capabilities may make this moot though”。这本质上是网络具有一种参考用户提供的subject/style图片来生成的能力。之前这种能力需要finetune模型来实现,之后应该会有一些方法,比如Retrieval Based模型,使得网络更容易实现这样的任务。可以让网络很快地学习新概念,这应该是大家都在期待的东西,值得进一步探索。
链接#
好玩的项目#

Twitter 上有人秀了一个利用4张手画的图片+ Live3D-v2+Stable Diffusion实现的Demo。猜测是用Live3D出动作和底图,然后拆帧利用SD的img2img功能做的?关键是保持角色的连续一致性了。原视频的动漫形象实际上还是有闪烁,我压缩成小GIF之后,看起来闪烁反而很少了。
text&image数据集#
英文#
-
训练BLIP的数据集 LAION子集,是用BLIP论文中提出的数据集筛选策略处理的LAION数据集,包含筛选过的合成的caption和原caption。质量肯定是比原版LAION高,也超过了100M,够用了。
-
facebook/pmd · Datasets at Hugging Face FLAVA这篇论文搞的开源数据集的一个汇总。PMD contains 70M image-text pairs in total with 68M unique images. The dataset contains pairs from Conceptual Captions, Conceptual Captions 12M, WIT, Localized Narratives, RedCaps, COCO, SBU Captions, Visual Genome and a subset of YFCC100M dataset. 有些数据集制作的时候不是为了V-L Pretraining任务,所以PMD做了些处理。开源可用的小数据集PMD基本都包括了,而且还是通过Huggingface的`datasets`这个库提供的,都整理好了,比较方便下载。
中文#
最近出来一些中文的大规模图文数据集,让我们感谢这些愿意开源数据集的大好人!
-
TaiSu(太素),166M图+219M文,提供了一个26G的CSV。是从华为的搜索引擎和中文维基搞到的搜索高频词,过滤后送到百度和必应搜索相关图片。拿这些裸数据(177M)训练一个CLIP,然后用这个CLIP去做retrieval任务。搞一个固定大小的Batch的脏图文数据,当一个pair的图比batch内其它所有图都更匹配对应描述,对应描述比所有其它描述都更匹配这个图片时(可以简述为batch内共轭最相似?),可以将这个pair保留下来。TauSu这里用的batch size是120。这种筛数据的方法的质量取决于batch size,但总体感觉是比LAION筛数据时那种卡一个阈值的思路更靠谱一点的。这种做法似乎不依赖于一个很强的预训练CLIP,挺有意思的。另外TaiSu也拿OFA去生成一些caption,然后再翻译成中文当做匹配的文本描述。这样,一张图可能有多个描述。
-
[Zero]{.underline} 23M,SO.com,360搜索搞的。这种图文匹配数据,一定是搞搜索的人最多,别人爬数据也大多从搜索引擎开始爬起。好奇会不会因为搞数据,导致百度,搜狗之类的搜索引擎流量暴涨。爬数据的流量和正常流量相比到底是什么量级?
-
[Noah-Wukong Dataset]{.underline} 100M。找了200K高频词,然后去百度搜索相关图片,爬到166M个pair,然后图片质量、文本描述质量分别筛了一些,构造了100M的图文数据集。
此外,还有WudaoMM(5M),Product1M(1M)似乎也是开源可用的中文数据集,但量级不大。
整体看下来似乎TaiSu的量级足够大,而且筛选方式更严苛一点,感觉数据质量相对较高。
这种数据集都是收集的图片链接,需要你自己下载图片。而图片链接经常失效,所以碰到开源就得赶紧下。过一年可能就只能下载整理得到一半图文pair了。
一些链接#
-
Public Prompts 一个收集基于SD的好看prompt、embedding、model的网站。收集的东西很少,但每个都挺好看。
-
Midjourney图+图->图示例(Twitter) Midjourney提供了用图+图合成新图的功能,效果很惊艳。如果想实现这个功能,几乎可以肯定Midjourney的链路中,包含一个image embedding到image的组件。就是类似于Image Variation的一个功能?但是如何适当地混合两个图片的embedding是个不好解决的问题。
-
GitHub - Coyote-A/ultimate-upscale-for-automatic1111 一个新的针对SD的超分工具,可以放大4倍原图。示例图挺惊艳。
-
Exploring Tokenizers from Hugging Face 分析了一下Huggingface提供的tokenizers。可以视作一个tokenizers基础知识普及。我没怎么接触过NLP,看NLP里的什么知识点都感觉哇...好新奇。
-
DreamShaper | Stable Diffusion Checkpoint | Civitai DreamShaper是一个新出现的finetune SD模型。这些爱好者们怎么一个个都能搞出这么好看的模型,我专门搞这个的,还一堆GPU,却吭哧吭哧啥也搞不出来。