本文由工具自动收集我在 Memos上记录的内容,汇总后得到。 Cursor帮忙实现了从API加载数据、解析时间字符串、内容处理正则等函数。
-
cleanlab/cleanvision: Automatically find issues in image datasets and practice data-centric computer vision (github.com) 能筛选数据集里的图片,找出有包括Low Information、Blurry在内的异常图片。
-
On the De-duplication of LAION-2B 也是一个给LAION去重的工作。不过这篇文章的思路不像Meta那篇,不是先聚类再两两求相似度,而是直接压缩CLIP特征,在压缩后的特征上批量求相似度。 ryanwebster90/snip-dedup (github.com)这里是代码。据说可以很快地搜索整个LAION2B的数据。
-
A PERCEPTUAL QUALITY ASSESSMENT EXPLORATION FOR AIGC IMAGES 收集了一个AI生成的图片数据集,然后人工打分。跑了一堆IQA算法,得到IQA算法在生成图片上的指标,然后计算了一下这些指标和人工打分的一致性。得到结论:the current IQA models are not well qualified to deal with AG IQA task and there is still a long way to go. 🐶
-
DiHT Facebook开源的对应于论文 Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training的代码库。一看就是仿照openai/clip写的。由于这个DiHT炼出来的CLIP:1. 对object、attribute等识别应该会更好。2. 完全不识字(去掉了需要网络做OCR的数据)。3. 相比于很短的几个词的prompt,更容易理解完整的句子。特点很鲜明,感觉在特定场景下很有用。
-
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning 改进了一下LoRA,提出了AdaLoRA。通过参数重要性动态调整LoRA引入的增量矩阵的rank,重要的权重对应的增量矩阵的rank高一些,反之则低一些。这样把可学习的参数量动态分配到不同layer和不同block的weights上。感觉是比较自然合理的做法。所以看这篇论文的重点应该就是怎么分了,分的方法合理不合理啥的。我看完感觉作者只考虑了参数量的分配,没考虑一个事实:可学习层在网络靠后所占的显存比网络靠前所占的显存少很多!涉及到需要保存中间激活值的问题。当然如果每层都要加一个lora矩阵的话就没啥影响了。作者的实验证明AdaLoRA在各个实验中,一般都比LoRA强一些。
-
EVA-02出来了。对应的技术报告是 EVA-02: A Visual Representation for Neon Genesis。EVA02系列是基于EVA-CLIP用MIM重建loss训练的。也有对应的CLIP版本。另外一个改进是在ViT上应用了一堆NLP领域对Transformer的改进trick。EVA2 ViT-L就可以在ImageNet上实现zero-shot 80%准确率。但是相比于Zero-Shot分类,其检索任务没有想象地那么强,和OpenAI开源的差不多。论文解释这个原因可能是因为检索任务同时要求CLIP文本编码能力足够强,但EVA-CLIP系列的语言分支都没有专门提升过。我觉得可能还有一个原因是EVA-CLIP用EVA2初始化,EVA2本身是在ImageNet外加一堆标准学术数据集上预训练的,可能对object识别类问题更有优势?
-
Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training 提出了一种LAION筛选策略:complexity (C)-删掉caption中甚至一个relationship都不包含的, actions (A)-删掉caption中没有action的, and text-spotting (T)-删掉caption中包含图片中文本的。前两个策略比较好懂,最后一个作者说这样可以不让网络消费权重去做OCR任务,专注于学习我们更关心的对象和关系。 作者的消融实验证实CAT策略里面,A策略会提升COCO这样的检索任务但降低ImageNet识别的能力。T策略则都会带来明显的提升。
-
SemDeDup: Data-efficient learning at web-scale through semantic deduplication 提出,使用语义去重之后的LAION数据集训练CLIP,能用50%的数据量+50%的迭代次数,实现和100%数据量+迭代次数的训练一致的性能。在多个数据集上的平均性能甚至数据少一点,性能反而更高了。论文提出的语义去重指首先对整个LAION的CLIP特征聚类,然后再每个类内求所有点直接相互距离,距离小于一个阈值的样本只保留一份。这种对数据的清洗方案值得参考。
-
缓解交叉熵过度自信的一个简明方案 苏剑林大神的一篇小教程,介绍了一种交叉熵函数的改进方法。交叉熵中不是包含一个log项吗,这个改进就是引入了一个系数,在log与不带log之间插值。其实不只是分类,现在生成任务也是常用交叉熵的。比如我之前写的 生成周刊第一期里介绍的MaskGIT或者VQGAN什么的,只要是预测离散token的地方,都可以用交叉熵,理论上也都能受益于这篇文章提出的对交叉熵的改进。
-
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU Huggingface介绍了一种利用LoRA+LLM.int8()实现单卡24GB训练20BLLM的技术。20B权重float32加载需要80GB,但int8加载只需要20GB。微调时,如果设置模型权重为int8,然后用float16或者bfloat16去训练LoRA引入的Adapter,就能实现标题所说的24GB微调20B模型。这种方法肯定对性能有一定影响,同时我个人感觉debug起来也比较麻烦,int8和float16交互,随便哪有问题就nan了。但这不没办法吗?2B的模型训练起来都麻烦,20B,能跑起来就不错了。
-
abacaj/transformers画了3张非常清晰的图,解释了一下NLP领域常见的Encoder、Decoder、Encoder-Decoder架构的区别与原理。画的浅显易懂,适合NLP初学者理清楚基本概念。
-
一个小小小工具: eriknyquist/duckargs。作用是你给它这样的字符串:
positional_arg1 positional_arg2 -i --int-val 4 -f 3.3 -F --file file_that_exists -a -b -c它自动给你生成如下的代码:
import argparse
def main():
parser = argparse.ArgumentParser(description='',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('positional_arg1', help='a string')
parser.add_argument('positional_arg2', help='a string')
parser.add_argument('-i', '--int-val', default=4, type=int, help='an int value')
parser.add_argument('-f', default=3.3, type=float, help='a float value')
parser.add_argument('-F', '--file', default='file_that_exists', type=argparse.FileType(), help='a filename')
parser.add_argument('-a', action='store_true', help='a flag')
parser.add_argument('-b', action='store_true', help='b flag')
parser.add_argument('-c', action='store_true', help='c flag')
args = parser.parse_args()感觉对于还在用argparse的同学是个利好。可惜,人生苦短,我用
python-fire。
- 从Huggingface训练大模型note里面看到他们很依赖transformers库里的一个debug class:
DebugUnderflowOverflow,这个类能wrap任何一个
nn.Module,当模型权重或者中间层输入输出出现inf、nan时将当前层之前固定数量的层的输入输出最大值打印出来,很适合debug fp16导致的nan之类的问题。
...
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[...]
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
You can see here, that `T5DenseGatedGeluDense.forward` resulted in output activations, whose absolute max value was
around 62.7K, which is very close to fp16's top limit of 64K.
...这种小工具函数感觉还挺有用的。
-
Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models是一篇利用SD训练好的UNet的中间特征做下游任务的论文。周一看到的 Unleashing Text-to-Image Diffusion Models for Visual Perception也是类似的思路。两个文章应该可以对比着看,似乎都是注意到CrossAttention中的attention map有很强的语义,然后想着利用一下。我表示谨慎看好这类型的文章,实用价值存疑?可能都是受到了DatasetGAN那一系列基于StyleGAN的中间特征的论文的启发。
-
kakao-ALIGN kakao开源的在COYO700M数据集上训练的ALIGN模型。ALIGN模型是Google的一篇类似于CLIP的文章,但是是在noisy的数据集上训练的。 align-base和CLIP的训练数据集完全不一样(21年前后),但用途类似,应该可以被用来做一些模型融合什么的。
作者设计了Prismer(棱角),又是一篇类似于BLIP2那种引入轻量的Adaptor来对齐纯视觉和纯文本预训练模型,来做文本预测相关任务的论文。使用预训练的CLIP(视觉)模型做Encoder,RoBERTa模型做Decoder。不同模态的视觉模型的预测结果+图片本身一起作为Encoder的输入,送入Decoder得到一段文本。在这样的图片+多模态condition -> 文本的接口下,做了VQA、Image Caption等任务,和BLIP等SOTA取得了相似的性能,但BLIP需要本文10-20倍的数据量去训练。
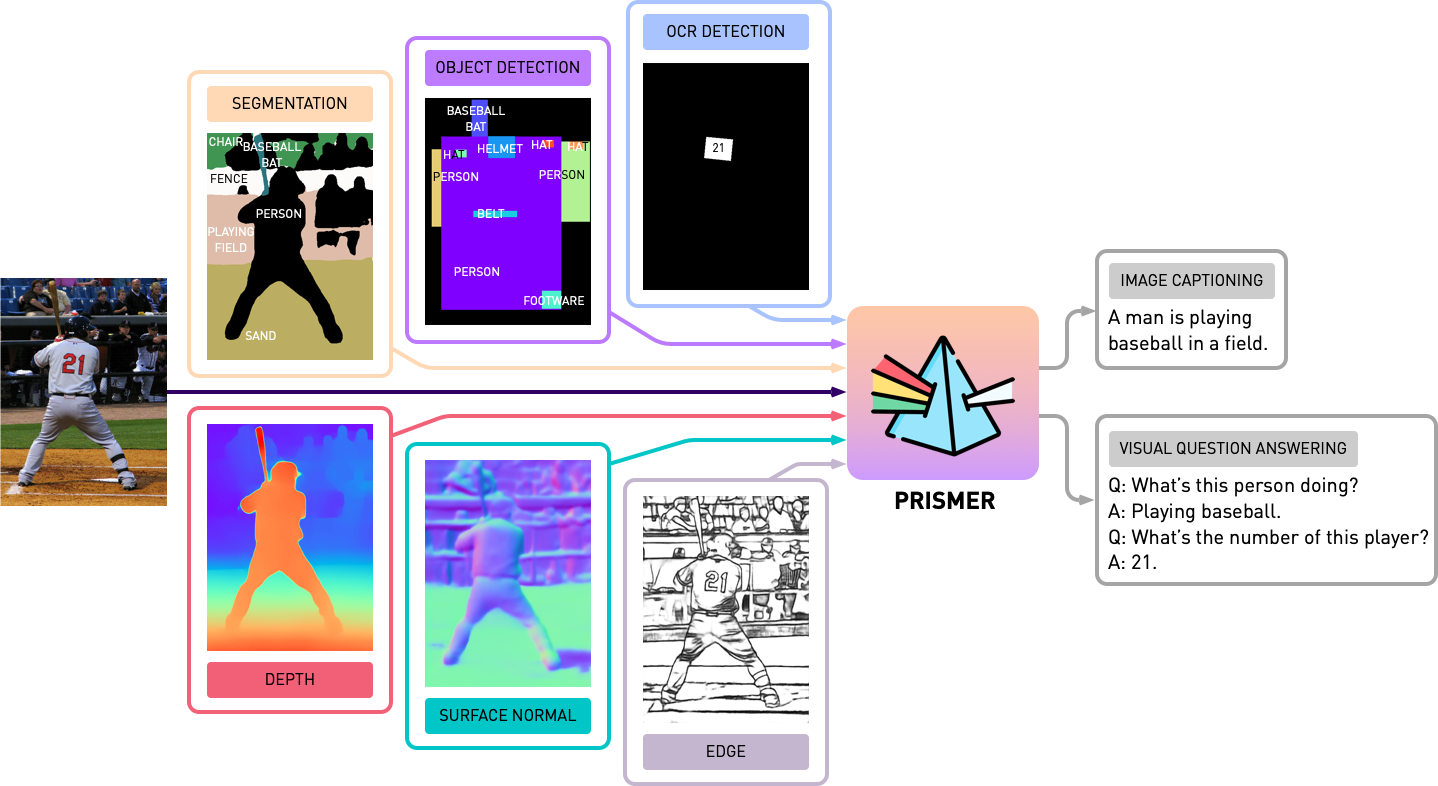
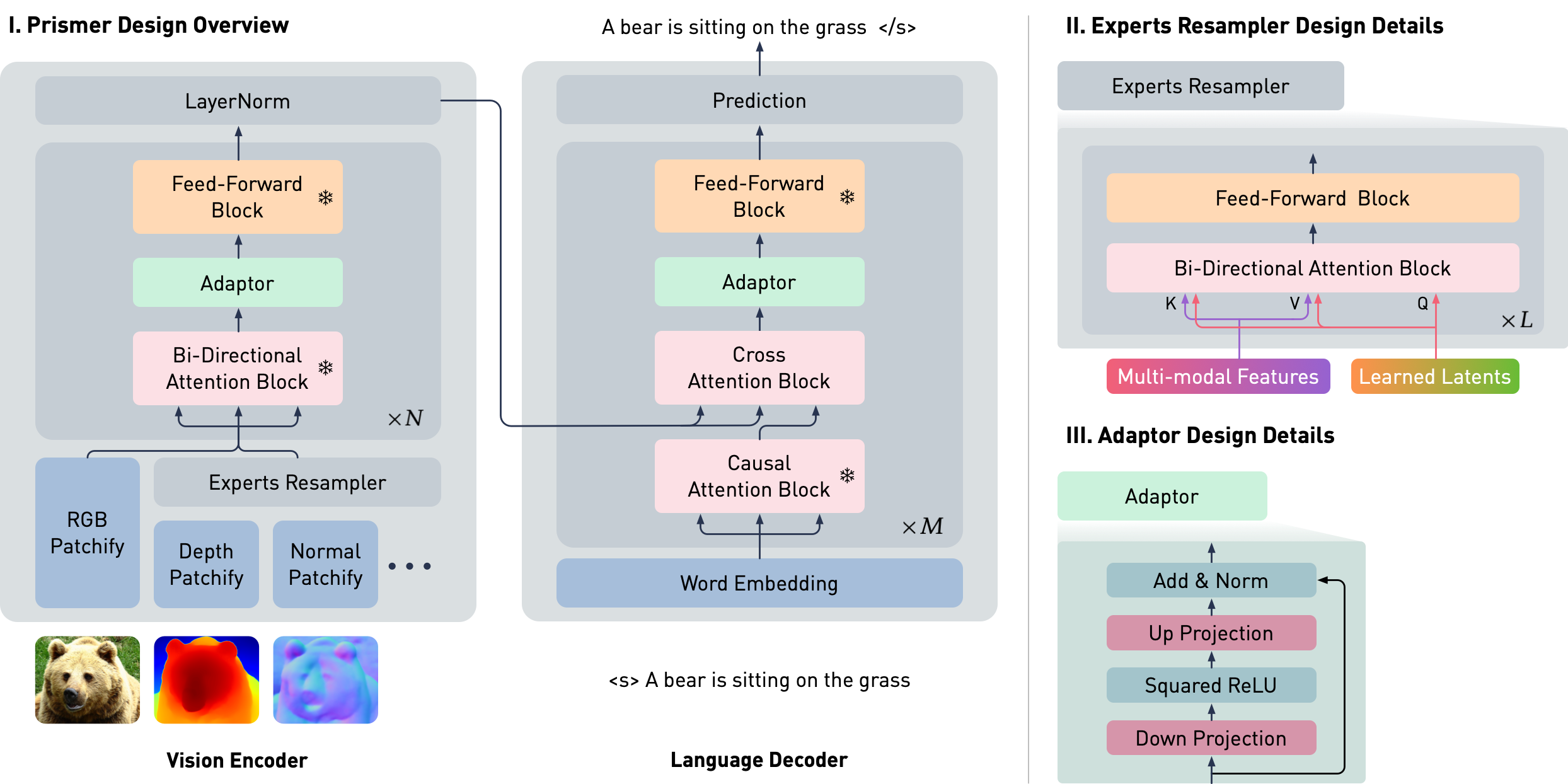
值得一提的是,Prismer很快就开源了论文和代码以及模型:
NVlabs/prismer。这份代码真是是近年来看到了开源清流了,质量非常高,包含训练等等内容。基本没封装,每个任务一个脚本解决问题,太棒了。
老黄不愧是卖卡的,更在乎大家用起来显卡,模型代码什么的他们也没啥业务用,藏着掖着没啥必要。
-
Flan UL2 vs Flan T5 XXL 对比Demo。我测了几个In Context Learning的案例,意外地发现FLAN T5 XXL优于Flan UL2,不知道Google说Flan UL2更好怎么体现?(其实我还是不是很懂怎么评测NLP大模型的好坏。
-
Booru style tag autocompletion for AUTOMATIC1111’s Stable Diffusion web UI 能在输入Tag时提供booru风格(如Danbooru)的TAG自动补全。
-
Unleashing Text-to-Image Diffusion Models for Visual Perception 认为T2I Diffusion Model包含着“high-level knowledge thanks to the vision-language pre-training”,这篇论文使用Diffusion网络中的中间特征,以及Cross-Attention 中的attention map一起去做感知任务,在referring image segmentation和depth estimation两个任务上取得了sota,表现不错。