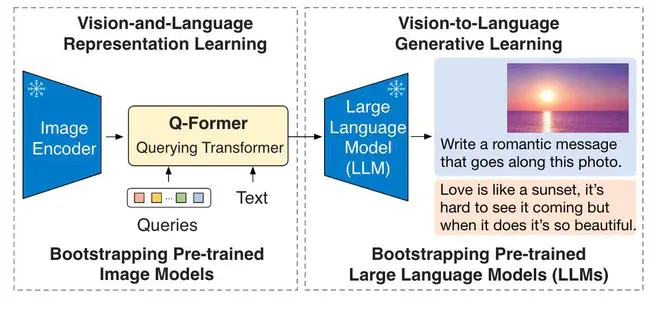
BLIP2 是BLIP团队的新作,核心共享是教给大家如何同时利用预训练视觉和语言模型实现多模态任务。BLIP2的同时利用了预训练的图片Encoder和LLM,可以复用LLM中存储的知识和Image Encoder的特征提取能力。为了建立Image Encoder和LLM两个单模态大模型的之间的关联,BLIP2设计了一个相对轻量的Q-Former结构,
BLIP2整个训练过程可以分为两个阶段,都是在训练Q-Former。第一阶段目的是从预训练的Image Encoder提取的特征中,抽取和text最相关的视觉特征;第二阶段则是将这些抽取的视觉特征经过线性映射后直接作为LLM的输入text embedding,即"soft visual prompts",然后借用LLM的语言建模能力输出期望的caption。
第一阶段:VL 表达学习#
这一阶段,BLIP2分别测试了用OpenAI-CLIP(ViT-L/14)和EVA-CLIP(ViT-G/14)做预训练视觉模型,使用其倒数第二次网络的输出作为Q-Former的condition。而可学习的Queries和Text Embedding一起作为Q-Former的输入。这一阶段Q-Former的输出则是一个与可学习的Queries tokens数一致的feature embeddings。详细地说,对于OpenAI-CLIP,视觉condition的size为257x768,可学习的Queries尺寸为32x768,网络的输出是32x768。
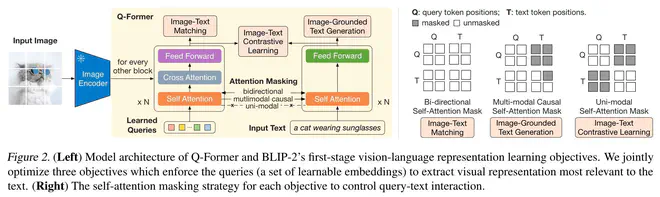
用于训练Q-Former的损失函数有三个:
-
Image-Text Contrastive Learning(ITC). 提取视觉特征时,网络的输入只有Learned Querie和Image Embedding,输出多个embedding(论文设置为32个);提取文本特征时,使用"[CLS]+prompt"的方式作为输入,选择[CLS]对应的embedding作为文本特征。多个视觉特征embedding和文本特征分别计算cosine相似度,选取相似度最高的embedding计算对比损失。
-
Image-Grounded Text Generation(ITG). 另外一个loss是给定Image时的Text生成损失。这个损失函数就是训练NLP任务用的LM损失,但增加了Image Embedding作为条件。看了一下实现代码,这一部分复用了ITC Loss单独提取视觉特征时计算的precomputed key and value hidden states,输入算是包含了Learned Queries、Image Embedding和text(部分)的信息。论文也着重强调了这里attention mask设置方法:所有Learned Queries都完全可见,但文本部分则按照LM建模的惯例,只能看到从左到右的部分文本。
-
Image-Text Matching(ITM). 这个loss建模文本图片匹配任务为匹配or不匹配二分类任务,QFormer同时输入Learned Queries、Image Embedding和text,得到了融合视觉和文本的多模态特征,这一特征送入线性的二分类器得到二分类结果。
训练时每个batch都计算这三个损失,然后相加作为最终损失函数。可以参考这一部分的 源代码,能对整个过程有更细致的了解。ITC和ITM损失函数都是在衡量文本和图片的匹配程度,而ITG是生成任务,能迫使Learned Queries从image embedding中提取那些和要重建的文本最相关的视觉特征,抛弃了和文本不相干的视觉特征。起到了信息瓶颈的作用,对齐了视觉特征和文本特征,因此论文强调ITG能辅助最小化ITC和ITM。
第二阶段:VL 生成学习#
第二阶段训练Q-Former和负责对齐Q-Former和LLM输入Embedding维度的FC层。Q-Former的输出是image
embedding和learned
queries(没有文本),即用于ITC损失时的视觉特征。送入FC后,得到LLM的输入text
embedding空间中的向量,接着送入LLM,得到输出文本。
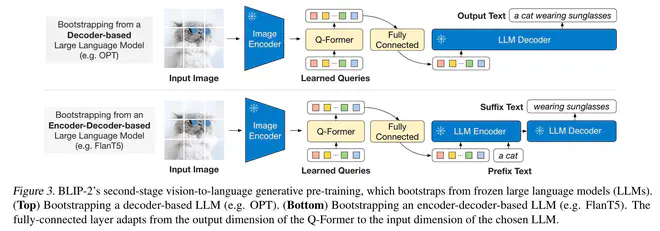
使用类似于FlanT5这样的Encoder-Decoder模型时,用prefix language modeling loss训练Q-fomer和FC;使用OPT这样的Decoder模型时,使用language modeling loss。由于LLM是固定的,因此最小化LM损失强依赖于Q-Former的输出经过FC转化后,能落入LLM输入空间,起到"soft visual prompts"的作用。第一阶段的预训练能保证这里Q-Former输出只包含与Text相关的视觉特征,视觉语言已经在一定程度上对齐。这样,第二阶段的训练能简化很多。
训练细节#
BLIP2复用了BLIP的训练数据,即LAION400M经过BLIP清洗合成得到的115M数据,以及COCO、VG等常见小数据集。预训练语言模型测试了OPT和FLAN-T5,预训练视觉模型则用了EVA-CLIP ViT-G/14和 OpenAI-CLIP ViT-L/14。
这里有点小遗憾,如果视觉模型用纯视觉的模型做点实验可能更有说服力?CLIP模型毕竟是视觉和语言一起训练的,得到的视觉特征已经和语言对齐一遍了。但也能理解,在100M上数据上预训练的纯视觉模型好像不多?只在ImageNet上预训练的模型没太大意义。
训练基于最大预训练模型(ViT-G and FlanT5-XXL)的Q-Former所需的计算量也就是16块A100不到6天(第一阶段)和3天(第二阶段),在VL预训练领域已经算少的了。
实验#
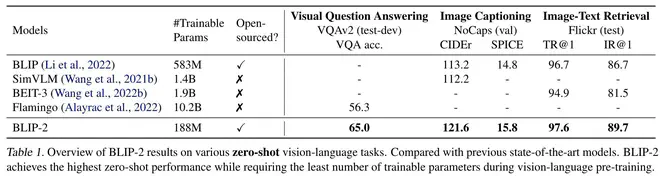
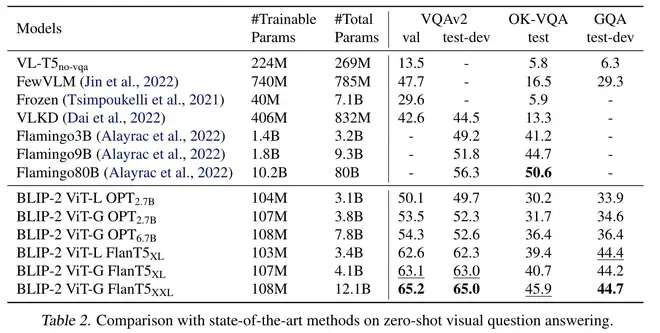
BLIP2的实验部分分为两部分,一部分是预训练后BLIP2的Zero-Shot能力,另一部分是在下游VQA、Image Captioning、Retrieval任务数据上finetune的效果。
我重点看了其Zero-Shot相关的实验。可以注意到,尽管BLIP2两个阶段的训练都和VQA这个任务无关,但Zero-Shot的VQA任务指标依然很不错,大部分设置都是SOTA。这一现象我最开始没想通,因为预训练时完全没有见过VQA那种问法的数据呀。第二阶段的预训练顶多能说是一个Image Caption任务(预训练任务是给定图片,预测训练集中图片对应的文本)。仔细看论文,论文强调VQA Zero-Shot的能力全部得益于LLM的能力,LLM是能理解"Question: {} Answer:“格式的文本的。这说明Q-Former成功地将图片特征转化为了文本token embedding级别的特征(注意,甚至不是语义级别的特征)。对于LLM而言,BLIP2做 VQA任务时,输入基本上对应于”<一堆对应图片的长文本> Question: {} Answer:" ,这一任务非常容易。
另外,BLIP2用多个预训练的视觉和文本模型做了实验,总体结论完全符合预期:基于的预训练模型越强,BLIP2越强。这事虽然符合直觉,但并不总是成立,比如 生成周刊·第一期中提到的,训练Muse模型时,VQGAN用更强的,生成效果反而没有更好。
BLIP2在论文中提到,in-context learning并不能提升VQA能力。论文指出这是因为训练时只用了一组又一组的image-text sample。但这点我没有太理解,in-context learning实际上考验的不是LLM的能力吗?LLM这里又没有被动过。Q-Former本质上是把图片转成了文本token embedding,和输入一长段描述图片的文本没啥本质区别。
demo和code#
BLIP2的作者团队非常良心,他们很快就积极地提供了预训练的 模型权重和代码,甚至提供了 Huggingface Demo试用。LAVIS这个代码库的组织也挺不错,没有Huggingface的Transfomers封装得那么多层,很好读。
我对比了一下BLIP2、BLIP、LAION-Coca、OFA以及微软的GIT的Image Captioning能力,BLIP2(Zero-Shot版本)非常稳定地优于其它方法。OFA应该是另外一个还不错的模型,可惜OFA对应的modelscope库实在是太复杂了,想模仿Transformers,但搞得很拉胯。宣传也不足,影响力甚至还比不上BLIP。
思考#
BLIP2第一阶段or第二阶段,Q-Former输出的视觉特征应该是我们一直在寻找的"生成型"的特征,而不是CLIP那种"判别型"的特征。理论上讲对文生图任务来说更为适用。