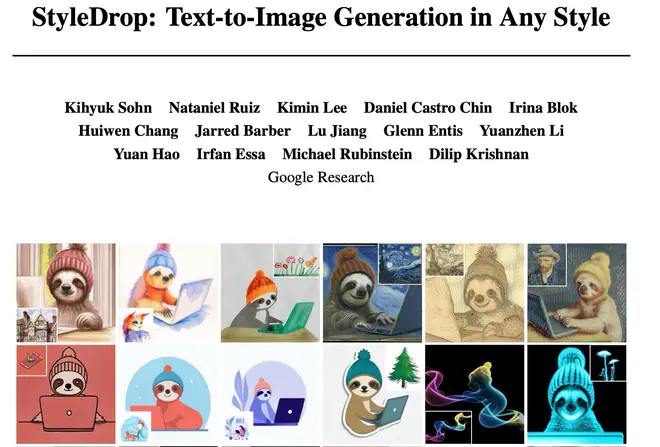
StyleDrop 尝试解决图片生成领域一个非常经典的问题:给定一张图片作为风格参考,生成一张该风格的新内容图片。其效果相比之前一众 style transfer 算法有了飞跃。
在其项目主页 StyleDrop: Text-to-Image Generation in Any Style 中有很多如下图这样的例子。生成图片不再有 patch-level 的重复感,图片内容干净整洁且没有受到风格图片内容的影响。

StyleDrop 的流程如下:
- 选定一个比较好的基底模型。 StyleDrop 选择了 Google 自家的 MUSE 模型。MUSE 模型不是一个 Diffusion 模型,而是 MIM 模型,图片被分为很多个小 patch ,最一开始每个 patch 都没有内容,MUSE 模型迭代地根据上一轮模型输出预测一部分 patch,直到所有的 patch 都被预测出来。我曾在 生成周刊·第一期 - wrong.wang 中详细地介绍过 MUSE 和其背后的 MaskGIT 算法,有兴趣可以再看一下。
- 使用少量(单张)Style 图片微调基底模型。 StyleDrop 微调模型时没有选择用 LoRA,而是在 Cross-Attention 层后引入了一个小的 Adapter 结构,引入了一些新模型参数。微调时,把 Style 图片的内容和样式都描述清楚,形成类似于 “xxx content in the yyy style”这样的 caption,内容描述要详尽,风格描述很简略也可以,甚至可以是 sks 那样的 rare token。这么做是为了避免图片内容被模型学到风格词中,应该是训练 Style LoRA 时大家的共识 trick 了。
- 用微调模型生成一批图片,挑出符合预期的结果,用筛选图片再微调一遍模型。由于上一步只用了单张图片,尽管标注已经相对详细,但上一步得到的模型的生成图片多半会有很多内容和风格没有解耦开的情况。StyleDrop 特意提出“Iterative Training with Feedback”策略。从前一轮的生成结果中,挑选出风格符合预期,内容贴合文本描述的图片。再重新微调模型。新的微调模型由于训练数据中包含同风格但不同内容,且描述很贴合的图片,更容易训练好。
在大略地了解了 StyleDrop 的整体思路后,再来关注其中的一些细节:
StyleDrop 每种风格都需要重新微调。论文中使用的默认配置是以学习率 3e-5 优化 1000step,然后从生成结果中人工选择 10 张图片。重新训练 1000 step,得到真正使用的微调模型。
在微调完模型后,类似于我之前介绍过的 DiffBlender - Scalable and Composable Multimodal Text-to-Image Diffusion Models - wrong.wang,StyleDrop 在前向时引入了类似于辅助 CFG 的思路。用微调后模型使用正向描述词的预测,与微调前模型使用正向描述词的预测相减,得到风格预测向量;用微调前模型使用正负描述词的预测之差来当做内容预测向量。这两向量乘各自的 Guidance scale ,与微调后模型+正向描述词的预测结果相加。
作者给了 Iterative Training 的消融结果:

如图 a,只有第一轮训练时,Adapter 训练很容易遇到过拟合问题,style 图片的内容和风格无法解耦开来,生成的香蕉都有和 style 图片类似的人的形状。先拿 round1 模型造一批数据,然后随机挑选/CLIP Score 筛选/人工筛选数据后,再训练第二轮 StyleDrop 模型,得到的结果能好一些,其中人工挑选和 CLIP Score 筛选的结果较为接近。
最后,为啥用 MUSE,不用 Imagen 呢?或者说,MIM 模型比 Diffusion 模型更适合这个任务吗?
作者用不同训练 setting,多次微调 Imagen ,发现需要 10 张风格图片以及详细地风格描述,才能在微调中学会参考图片的风格。而 MUSE 只需要单张图片与简略的风格描述就能学会新风格。即作者认为,仅有少量数据时,MUSE 比 Imagen 更容易学会新风格。

我对作者这个结论是存疑的。微调 MUSE 时,作者使用了特殊设计的 Adapter 结构,没有用 LoRA 这类普通的结构。由于训练图片很少,用训练图片微调网络中哪些参数,或者设计怎样的 Adapter 结构,一定对结果影响很大。我个人觉得给 Diffusion 模型设计更合适的 Adapter 结果,应该也可以做出来类似于 StyleDrop 的结果。StyleAlign 中提出的 Attention 层中的类 AdaIN 设计应该是一个很好的 Adapter 设计参考。可以用可学习参数作为类 AdaIN 结构所需的信息。